




El archivo robots.txt del blog personal de John Mueller de Google se convirtió en un foco de interés cuando alguien en Reddit afirmó que el blog de Mueller había sido atacado por el sistema de contenido útil y posteriormente desindexado. La verdad resultó ser menos dramática que eso, pero aun así era un poco extraña.
Publicación del subreddit de SEO
La saga del archivo robots.txt de John Mueller comenzó cuando un Redditor publicó que el sitio web de John Mueller estaba desindexado y que entraba en conflicto con el algoritmo de Google. Pero por más irónico que sea, eso nunca iba a ser así porque todo lo que tomó fueron unos segundos para cargar el archivo robots.txt del sitio web y ver que algo extraño estaba sucediendo.
Aquí está la parte superior del archivo robots.txt de Mueller, que presenta un huevo de Pascua comentado para aquellos que echen un vistazo.
Lo primero que no se ve todos los días es un rechazo en el archivo robots.txt. ¿Quién usa su archivo robots.txt para decirle a Google que no rastree su archivo robots.txt?
Ahora sabemos.
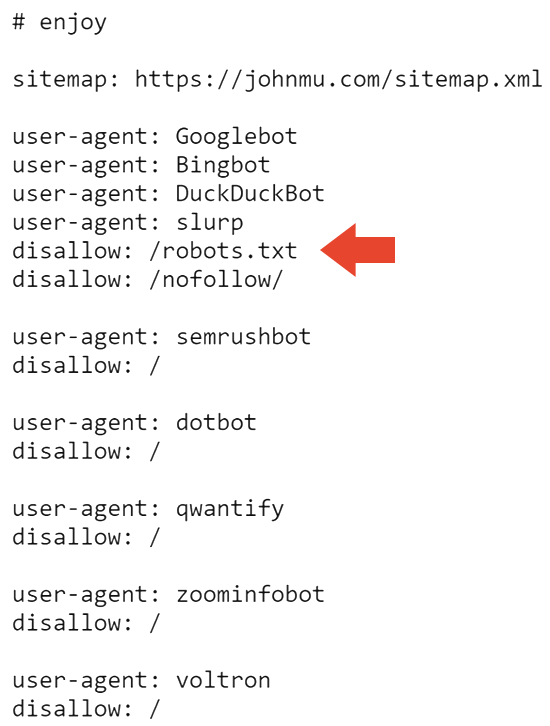
La siguiente parte del archivo robots.txt impide que todos los motores de búsqueda rastreen el sitio web y el archivo robots.txt.
Eso probablemente explica por qué el sitio está desindexado en Google. Pero no explica por qué Bing todavía lo indexa.
Pregunté y Adam Humphreys, desarrollador web y SEO (perfil de LinkedIn), sugirió que podría ser que Bingbot no haya estado en el sitio de Mueller porque es un sitio web en gran medida inactivo.
Adam me envió un mensaje con sus pensamientos:
“Agente de usuario: *
No permitir: /topsy/
No permitir: /crets/
No permitir: /hidden/file.htmlEn esos ejemplos, no se encontrarían las carpetas y el archivo en esa carpeta.
Está diciendo que no se permita el archivo robots que Bing ignora pero Google escucha.
Bing ignoraría los robots implementados incorrectamente porque muchos no saben cómo hacerlo. “
Adam también sugirió que tal vez Bing ignoró por completo el archivo robots.txt.
Me lo explicó de esta manera:
“Sí o elige ignorar una directiva de no leer un archivo de instrucciones.
Es probable que se ignoren las instrucciones de los robots en Bing implementadas incorrectamente. Ésta es la respuesta más lógica para ellos. Es un archivo de direcciones”.
El archivo robots.txt se actualizó por última vez entre julio y noviembre de 2023, por lo que es posible que Bingbot no haya visto el último archivo robots.txt. Esto tiene sentido porque el sistema de rastreo web IndexNow de Microsoft prioriza el rastreo eficiente.
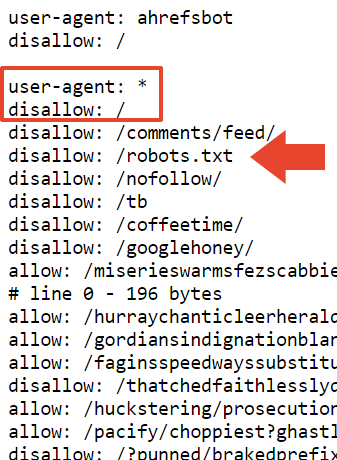
Uno de los directorios bloqueados por el archivo robots.txt de Mueller es /nofollow/ (que es un nombre extraño para una carpeta).
Básicamente no hay nada en esa página excepto algo de navegación del sitio y la palabra Redirector.
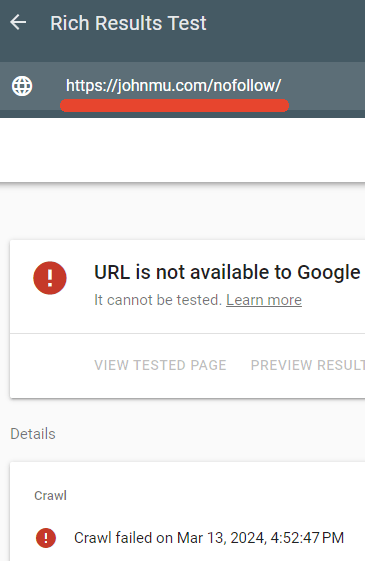
Probé para ver si el archivo robots.txt realmente estaba bloqueando esa página y así fue.
El probador de resultados enriquecidos de Google no pudo rastrear la página web /nofollow/.
La explicación de John Mueller
Mueller pareció divertido que se prestara tanta atención a su archivo robots.txt y publicó una explicación en LinkedIn de lo que estaba pasando.
El escribio:
“Pero, ¿qué pasa con el expediente? ¿Y por qué su sitio está desindexado?
Alguien sugirió que podría deberse a los enlaces a Google+. Es posible. Y volviendo al archivo robots.txt… está bien; quiero decir, es como lo quiero y los rastreadores pueden manejarlo. O deberían poder hacerlo, si siguen el RFC9309”.
Luego dijo que el nofollow en el archivo robots.txt era simplemente para evitar que fuera indexado como un archivo HTML.
Él explicó:
“”disallow: /robots.txt” – ¿Esto hace que los robots giren en círculos? ¿Esto desindexa su sitio? No.
Mi archivo robots.txt tiene muchas cosas y está más limpio si no se indexa con su contenido. Esto simplemente bloquea el rastreo del archivo robots.txt con fines de indexación.
También podría usar el encabezado HTTP x-robots-tag con noindex, pero de esta manera también lo tengo en el archivo robots.txt”.
Mueller también dijo esto sobre el tamaño del archivo:
“El tamaño proviene de las pruebas de las diversas herramientas de prueba de robots.txt en las que mi equipo y yo hemos trabajado. El RFC dice que un rastreador debe analizar al menos 500 kibibytes (me gusta extra para la primera persona que explique qué tipo de refrigerio es ese). Hay que parar en algún lado, se podrían hacer páginas infinitamente largas (y yo lo he hecho, y mucha gente lo ha hecho, algunas incluso a propósito). En la práctica, lo que sucede es que el sistema que verifica el archivo robots.txt (el analizador) hará un corte en alguna parte”.
También dijo que agregó una prohibición en la parte superior de esa sección con la esperanza de que se considere una “prohibición general”, pero no estoy seguro de qué prohibición está hablando. Su archivo robots.txt tiene exactamente 22,433 no permitidos.
El escribio:
“Agregué un” no permitir: / “en la parte superior de esa sección, así que espero que se considere una no autorización general. Es posible que el analizador se corte en un lugar incómodo, como una línea que tiene “allow: /cheeseisbest” y se detiene justo en “/”, lo que pondría al analizador en un punto muerto (y, ¡trivia! la regla de permiso). se anulará si tiene tanto “allow: /” como “disallow: /”). Sin embargo, esto parece muy improbable”.
Y ahí está. Los extraños robots.txt de John Mueller.
Robots.txt visible aquí:
https://johnmu.com/robots.txt

