




Hugging Face presentó recientemente Falcon 180B, el modelo de lenguaje grande de código abierto más grande que se dice que funciona tan bien como la IA de última generación de Google, Palm 2. Y tampoco tiene barreras de seguridad que le impidan crear resultados inseguros o dañinos.
Falcon 180B logra un rendimiento de vanguardia
La frase “estado del arte” significa que algo está funcionando al más alto nivel posible, igualando o superando el ejemplo actual de lo mejor.
Es un gran problema cuando los investigadores anuncian que un algoritmo o un modelo de lenguaje grande logra un rendimiento de vanguardia.
Y eso es exactamente lo que dice Hugging Face sobre el Falcon 180B.
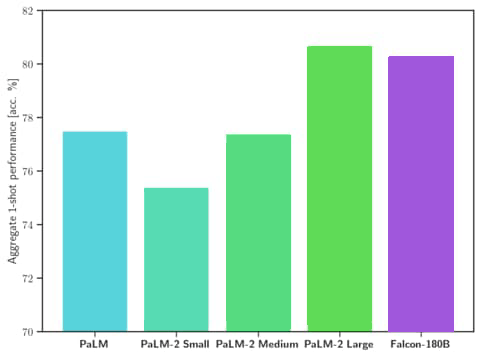
Falcon 180B logra un rendimiento de última generación en tareas de lenguaje natural, supera a los modelos de código abierto anteriores y también “rivaliza” con el Palm 2 de Google en rendimiento.
Esos tampoco son sólo alardes.
La afirmación de Hugging Face de que el Falcon 180B rivaliza con el Palm 2 está respaldada por datos.
Los datos muestran que Falcon 180B supera al modelo anterior de código abierto más potente, Llama 270B, en una variedad de tareas utilizadas para medir qué tan poderoso es un modelo de IA.
Falcon 180B incluso supera al GPT-3.5 de OpenAI.
Los datos de las pruebas también muestran que el Falcon 180B funciona al mismo nivel que el Palm 2 de Google.
Captura de pantalla de comparación de rendimiento
El anuncio explicaba:
“Falcon 180B es el mejor LLM lanzado abiertamente en la actualidad, superando a Llama 2 70B y GPT-3.5 de OpenAI…
Falcon 180B normalmente se ubica en algún lugar entre GPT 3.5 y GPT4 dependiendo del punto de referencia de evaluación…”
El anuncio continúa implicando que un ajuste adicional del modelo por parte de los usuarios puede mejorar aún más el rendimiento.
Problemas técnicos menores que enturbian la indexación, como activar redirecciones 301 mediante enlaces internos a URL antiguas que se han actualizado con una estructura de categorías.
Conjunto de datos utilizado para entrenar Falcon 180B
Hugging Face publicó un artículo de investigación (versión PDF aquí) que contiene detalles del conjunto de datos utilizado para entrenar al Falcon 180B.
Se llama The RefinedWeb Dataset.
Este conjunto de datos consta únicamente de contenido de Internet, obtenido del Common Crawl de código abierto, un conjunto de datos de la web disponible públicamente.
Posteriormente, el conjunto de datos se filtra y se somete a un proceso de deduplicación (la eliminación de datos duplicados o redundantes) para mejorar la calidad de lo que queda.
Lo que los investigadores están tratando de lograr con el filtrado es eliminar el spam generado por máquinas, el contenido repetido, el contenido repetitivo, el contenido plagiado y los datos que no son representativos del lenguaje natural.
El artículo de investigación explica:
“Debido a errores de rastreo y fuentes de baja calidad, muchos documentos contienen secuencias repetidas: esto puede causar un comportamiento patológico en el modelo final…
…Una fracción significativa de las páginas es spam generado automáticamente, compuesto predominantemente de listas de palabras clave, texto repetitivo o secuencias de caracteres especiales.
Estos documentos no son adecuados para el modelado del lenguaje…
…Adoptamos una agresiva estrategia de deduplicación, combinando coincidencias inexactas de documentos y eliminación de secuencias exactas”.
Aparentemente se vuelve imperativo filtrar y limpiar el conjunto de datos porque se compone exclusivamente de datos web, a diferencia de otros conjuntos de datos que agregan datos no web.
Los esfuerzos de los investigadores por filtrar las tonterías dieron como resultado un conjunto de datos que, según afirman, es tan bueno como conjuntos de datos más seleccionados que se componen de libros pirateados y otras fuentes de datos no web.
Concluyen afirmando que su conjunto de datos es un éxito:
“Hemos demostrado que el filtrado y la deduplicación estrictos podrían dar como resultado un conjunto de datos web de cinco billones de tokens adecuado para producir modelos competitivos con la última tecnología, superando incluso a los LLM formados en corpus seleccionados”.
Falcon 180B no tiene barandillas
Lo notable del Falcon 180B es que no se ha realizado ningún ajuste de alineación para evitar que genere resultados dañinos o inseguros ni nada para evitar que invente hechos y mienta abiertamente.
Como consecuencia, el modelo se puede ajustar para generar el tipo de resultados que no se pueden generar con productos de OpenAI y Google.
Esto aparece en una sección del anuncio titulada limitaciones.
Hugging Face aconseja:
“Limitaciones: el modelo puede producir y producirá información objetivamente incorrecta, hechos y acciones alucinantes.
Como no se ha sometido a ningún ajuste/alineación avanzada, puede producir resultados problemáticos, especialmente si se le solicita que lo haga”.
Uso comercial del Falcon 180B
Hugging Face permite el uso comercial del Falcon 180B.
Sin embargo, se publica bajo una licencia restrictiva.
Hugging Face recomienda a quienes deseen utilizar Falcon 180B que consulten primero con un abogado.
Falcon 180B es como un punto de partida
Por último, el modelo no ha recibido capacitación, lo que significa que debe ser entrenado para ser un chatbot de IA.
Entonces es como un modelo base que necesita más para convertirse en lo que los usuarios quieran que sea. Hugging Face también lanzó un modelo de chat, pero aparentemente es “simple”.
Abrazando la cara explica:
“El modelo base no tiene formato de aviso. Recuerde que no es un modelo conversacional ni está entrenado con instrucciones, así que no espere que genere respuestas conversacionales: el modelo previamente entrenado es una excelente plataforma para realizar ajustes adicionales, pero probablemente no debería usarlo directamente de inmediato.
El modelo Chat tiene una estructura de conversación muy simple”.
Lea el anuncio oficial:
Extiende tus alas: Falcon 180B ya está aquí
Imagen destacada de Shutterstock/Giu Studios

